We broke this integration problem down into four categories:
- Service control and deployment
- Inter-service communication
- Infrastructure integration
- Engineering support and education
Service Control and Deployment
We use a custom extension of
Capistrano (we call it ‘Skycap’) to deploy services and manage those services at runtime. It is important for us to manage both containerized and classic services through a single, well-established framework. We also need to isolate Skycap from the inevitable breaking changes inherent in an actively-developed tool like Kubernetes.
To handle this, we use wrappers in to our service control framework that isolate kubectl behind Skycap and handle issues like ignoring spurious log messages.
Deployment adds a layer of complexity for us. Docker images are a great way to package software, but historically, we’ve deployed from source, not packages. Our engineering team expects that making changes to source is sufficient to get their work released; devs don’t expect to handle additional packaging steps. Rather than rebuild our entire deployment and orchestration framework for the sake of containerization, we use a continuous integration pipeline for our containerized services. We automatically build a new Docker image for every commit to a project, and then we tag it with the Mercurial (Hg) changeset number of that commit. On the Skycap side, a deployment from a specific Hg revision will then pull the Docker images that are tagged with that same revision number.
We reuse container images across multiple environments. This requires environment-specific configuration to be injected into each container instance. Until recently, we used similar source-based principles to inject these configuration values: each container would copy relevant configuration files from Hg by cURL-ing raw files from the repo at run time. Network availability and variability are a challenge best avoided, though, so we now load the configuration into Kubernetes’
ConfigMap feature. This not only simplifies our Docker images, but it also makes pod startup faster and more predictable (because containers don’t have to download files from Hg).
Inter-service communication
Our services communicate using two primary methods. The first, message brokering, is typical for process-to-process communication within the Skytap platform. The second is through direct point-to-point TCP connections, which are typical for services that communicate with the outside world (such as web services). We’ll discuss the TCP method in the next section, as a component of infrastructure integration.
Managing direct connections between pods in a way that services can understand is complicated. Additionally, our containerized services need to communicate with classic VM-based services. To mitigate this complexity, we primarily use our existing message queueing system. This helped us avoid writing a TCP-based service discovery and load balancing system for handling traffic between pods and non-Kubernetes services.
This reduces our configuration load—services only need to know how to talk to the message queues, rather than to every other service they need to interact with. We have additional flexibility for things like managing the run-state of pods; messages buffer in the queue while nodes are restarting, and we avoid the overhead of re-configuring TCP endpoints each time a pod is added or removed from the cluster. Furthermore, the MQ model allows us to manage load balancing with a more accurate ‘pull’ based approach, in which recipients determine when they are ready to process a new message, instead of using heuristics like ‘least connections’ that simply count the number of open sockets to estimate load.
Migrating MQ-enabled services to Kubernetes is relatively straightforward compared to migrating services that use the complex TCP-based direct or load balanced connections. Additionally, the isolation provided by the message broker means that the switchover from a classic service to a container-based service is essentially transparent to any other MQ-enabled service.
Infrastructure Integration
As an infrastructure provider, we face some unique challenges in configuring Kubernetes for use with our platform.
AWS&
GCP provide out-of-box solutions that simplify Kubernetes provisioning but make assumptions about the underlying infrastructure that do not match our reality. Some organizations have purpose-built data centers. This option would have required us to abandon our existing load balancing infrastructure, our Puppet based provisioning system and the expertise we’d built up around these tools. We weren’t interested in abandoning the tools or our vested experience, so we needed a way to manage Kubernetes that could integrate with our world instead of rebuild it.
So, we use Puppet to provision and configure VMs that, in turn, run the Skytap Platform. We wrote custom deployment scripts to install Kubernetes on these, and we coordinate with our operations team to do capacity planning for Kube-master and Kube-node hosts.
In the previous section, we mentioned point-to-point TCP-based communication. For customer-facing services, the pods need a way to interface with Skytap’s layer 3 network infrastructure. Examples at Skytap include our web applications and API over HTTPS, Remote Desktop over Web Sockets, FTP, TCP/UDP port forwarding services, full public IPs, etc. We need careful management of network ingress and egress for this external traffic, and have historically used
F5 load balancers. The MQ infrastructure for internal services is inadequate for handling this workload because the protocols used by various clients (like web browsers) are very specific and TCP is the lowest common denominator.
To get our load balancers communicating with our Kubernetes pods, we run the kube-proxy on each node. Load balancers route to the node, and kube-proxy handles the final handoff to the appropriate pod.
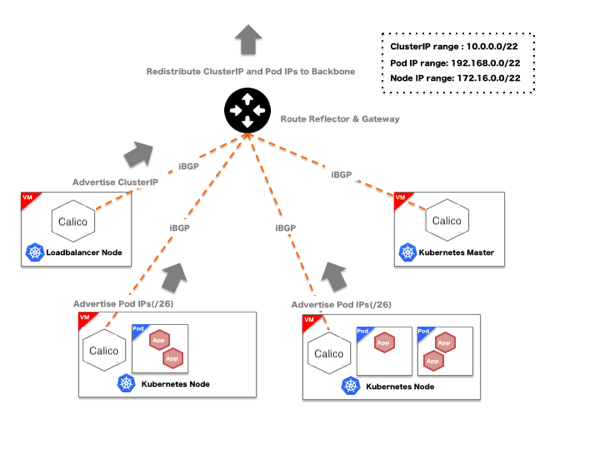
We mustn’t forget that Kubernetes needs to route traffic between pods (for both TCP-based and MQ-based messaging). We use the
Calico plugin for Kubernetes networking, with a specialized service to reconfigure the F5 when Kubernetes launches or reaps pods. Calico handles route advertisement with
BGP, which eases integration with the F5.
F5s also need to have their
load balancing pool reconfigured when pods enter or leave the cluster. The F5 appliance maintains a pool of load-balanced back-ends; ingress to a containerized service is directed through this pool to one of the nodes hosting a service pod. This is straightforward for static network configurations – but since we're using Kubernetes to manage pod replication and availability, our networking situation becomes dynamic. To handle changes, we have a 'load balancer' pod that monitors the Kubernetes svc object for changes; if a pod is removed or added, the ‘load balancer’ pod will detect this change through the svc object, and then update the F5 configuration through the appliance's web API. This way, Kubernetes transparently handles replication and failover/recovery, and the dynamic load balancer configuration lets this process remain invisible to the service or user who originated the request. Similarly, the combination of the Calico virtual network plus the F5 load balancer means that TCP connections should behave consistently for services that are running on both the traditional VM infrastructure, or that have been migrated to containers.
![kubernetes_f5_messaging.png]()
With dynamic reconfiguration of the network, the replication mechanics of Kubernetes make horizontal scaling and (most) failover/recovery very straightforward. We haven’t yet reached the reactive scaling milestone, but we've laid the groundwork with the Kubernetes and Calico infrastructure, making one avenue to implement it straightforward:
- Configure upper and lower bounds for service replication
- Build a load analysis and scaling service (easy, right?)
- If load patterns match the configured triggers in the scaling service (for example, request rate or volume above certain bounds), issue: kubectl scale --replicas=COUNT rc NAME
This would allow us fine-grained control of autoscaling at the platform level, instead of from the applications themselves – but we’ll also evaluate
Horizontal Pod Autoscaling in Kubernetes; which may suit our need without a custom service.
Keep an eye on
our GitHub account and the
Skytap blog; as our solutions to problems like these mature, we hope to share what we’ve built with the open source community.
Engineering Support
A transition like our containerization project requires the engineers involved in maintaining and contributing to the platform change their workflow and learn new methods for creating and troubleshooting services.
Because a variety of learning styles require a multi-faceted approach, we handle this in three ways: with documentation, with direct outreach to engineers (that is, brownbag sessions or coaching teams), and by offering easy-to-access, ad-hoc support.
We continue to curate a collection of documents that provide guidance on transitioning classic services to Kubernetes, creating new services, and operating containerized services. Documentation isn’t for everyone, and sometimes it’s missing or incomplete despite our best efforts, so we also run an internal #kube-help Slack channel, where anyone can stop in for assistance or arrange a more in-depth face-to-face discussion.
We have one more powerful support tool: we automatically construct and test prod-like environments that include this Kubernetes infrastructure, which allows engineers a lot of freedom to experiment and work with Kubernetes hands-on. We explore the details of automated environment delivery in more detail in this post.
Final Thoughts
We’ve had great success with Kubernetes and containerization in general, but we’ve certainly found that integrating with an existing full-stack environment has presented many challenges. While not exactly plug-and-play from an enterprise lifecycle standpoint, the flexibility and configurability of Kubernetes still remains a very powerful tool for building our modularized service ecosystem.
We love application modernization challenges. The Skytap platform is well suited for these sorts of migration efforts – we run Skytap in Skytap, of course, which helped us tremendously in our Kubernetes integration project. If you’re planning modernization efforts of your own, connect with us, we’re happy to help.
--Shawn Falkner-Horine and Joe Burchett, Tools and Infrastructure Engineering, Skytap